
.png)
.png)
.png)

C语言9,字符串和字符串函数
C语言9,字符串和字符串函数
9.1 表示字符串和字符串 I/O
9.1.1 在程序中定义字符串
9.1.1.1 字符串字面量
用双引号括起来的内容称为字符串字面量, 也叫字符串常量
char[10] = "hello!";
双引号中的字符和编译器自动加入末尾的\0 字符,都作为字符串存储在内存中
如果字符串字面量之间没有间隔,或者用空白字符分隔,C 会将其视为串联起来的字符串字面量
字符串常量属于静态存储类别,在整个程序的生命周期内存在,用双引号括起来的内容被视为指向该字符串存储位置的指针
9.1.1.2 字符串数组和初始化
定义字符串数组时,必须让编译器知道需要多少空间
char[10] 中的[10]就是指定数组的大小
在指定数组大小时,要确保数组中的元素个数至少比字符串长度多 1(为了容纳空字符)
多的元素被自动化初始为\0
如果省略声明数组的大小,编译器会自动计算数组的大小
只能用在初始化数组时
char[] 就是省略了声明数组大小
还可以用指针表示法创建字符串
char *pt1 = "Something is pointing at me.";
该声明与下面的声明相同
char ar1[] = "Something is pointing at me.";
pt1 和 ar1 都是该字符串的地址
但是这两种形式并不完全相同
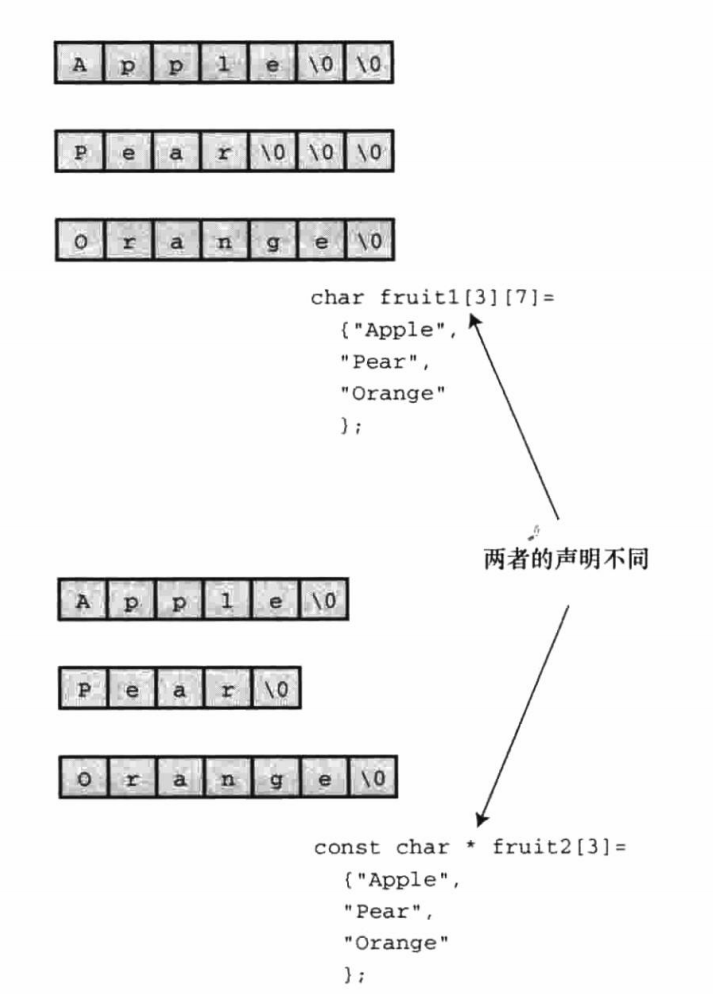
9.1.1.3 数组和指针
核心:初始化数组把静态存储区的字符串拷贝到数组中,而初始化指针只把字符串的地址拷贝给指针
以上面的声明为例:
数组形式(ar1[ ]) 在计算机的内存中分配一个内含 29 个元素的数组(包括空字符),每个元素被初始化为字符串字面量对应的字符。通常字符串都作为可执行文件的一部分储存在数据段中。当把程序载入内存时,也载入了程序中的字符串。字符串储存在静态储存区。 但是,程序在开始运行时才会为该数组分配内存。此时,才将数组拷贝到数组中。此时字符串有两个副本,一个是在静态内存中的字符串字面量,一个是储存在 ar1 数组中的字符串
此后,编译器便把数组名 ar1 识别为该数组首元素地址(&ar1[0])的别名。ar1 是地址变量,不能进行更改
指针形式(*pt1)也使得编译器为字符串在静态存储区预留 29 个元素的空间。另外,一旦开始执行程序,它会为指针变量 pt1 留出一个储存位置,并把字符串的地址储存在指针变量中。该变量最初指向该字符串的首字符,但是它的值可以改变
9.1.1.4 数组和指针的区别
char first[] = "hello";
const char *second = "world"; //建议在把指针初始化为字符串字面量时使用const限定符
两者主要的区别是:数组名 first 是常量,而指针名 second 是变量
两者都可以进行数组表示法
两者都可以进行指针加减操作
只有指针表示法可以进行递增操作
while(*(second) != '\0'){
putchar(*(second++));
}
如果不修改字符串,尽量不要用指针指向字符串字面量
9.1.1.5 字符串数组
如果创建一个字符数组会很方便,可以通过数组下标访问过个不同的字符串
两种方式:指向字符串的指针数组和 char 类型数组的数组
#include<stdio.h>
#define SLEN 40
#define LIM 5
int main(void){
const char *mytalents[LIM] = { //char类型数组的数组
"the first massage",
"the second massmge",
"something good","nice",
"understand it"
};
char yourtalents[LIM][SLEN] = { //指向字符串的指针数组
"Walking in a straight line",
"go go go haizaigo",
"It's my Go",
"understand it",
"cwecsdcrs"
};
return 0;
}
两者都代表 5 个字符串。使用一个下标表示一个字符串,使用两个下标时表示一个字符
区别:
mytalents 数组是一个内含 5 个指针的数组,在系统中占用 40 字节,而 yourtalents 是一个内含 5 个数组的数组,每个数组内含 40 个 char 类型的值,共占 200 字节
mytalents 中的指针指向初始化时所用的字符串字面量的位置,这些字符串字面量被储存在静态内存中;
而 yourtalents 中的数组则储存着字符串字面量的副本,所以每个字符串都被储存了两次
此外,yourtalents 中的每个元素的大小必须相同,而且是能储存的最长字符串的大小
我们可以把yourtalents想象成矩形二维数组每行长度相同
把mytalents想象成不规则的数组,每行长度不同,如下图(mytalents数组的指针元素所指向的字符串不必存储在连续的内存中)
综上:
如果要用数组表示一系列待显示的字符串,请使用指针数组,因为它效率更高
如果要改变字符串或为字符串输入预留空间,不要使用指向字符串字面量的指针
9.1.2 指针和字符串
实际上,字符串的绝大多数操作都是通过指针完成的,下面的程序是示例
#include <stdio.h>
int main(){
const char * mesg = "hello world";
const char * copy;
copy = mesg;
printf("%s\n",copy);
printf("mesg = %s; &mesg = %p; value = %p\n", mesg, &mesg, mesg);
printf("copy = %s; © = %p; value = %p\n", copy, ©, copy);
return 0;
}
输出结果:
hello world
mesg = hello world; &mesg = 000000000061FE18; value = 0000000000404000
copy = hello world; © = 000000000061FE10; value = 0000000000404000
两者的值都是0000000000404000,说明它们指向同一个位置。因此。程序并未拷贝字符串
语句 copy = mesg把mesg的值赋给copy,即让copy也指向mesg指向的字符串
如果需要拷贝数组,可以使用strcpy()或strncpy()函数,稍后介绍
9.2 字符串输入
如果想把一个字符串读入程序,首先要预留空间,然后用输入函数获取字符串
- gets()
- fgets()
- gets_s()
- scanf()
9.2.1 分配空间
最简单的办法
char name[81];
为字符串分配内存后,便可读入字符串:用sacnf(), gets() 和fgets()
9.2.2 gets()函数
gets()函数已过时,且有安全性问题,慎用
在读取字符串时,scanf()和转换说明%s只能读取一个单词
而gets()可以读取整行输入,直到遇到换行符,然后丢弃换行符,储存其它字符,并在这些字符的末尾添加一个空字符使其成为一个C字符串
它经常和puts()函数配对使用,该函数用于显示字符串,并在末尾添加换行符
#include <stdio.h>
#define STLEN 81
int main(void){
char words[STLEN];
puts("Enter a string, please.");
gets(words); //典型用法
printf("Your string twice:\n");
printf("%s\n", words);
puts(words);
return 0;
}
输出结果:
Enter a string, please.
qwerywqfyt
Your string twice:
qwerywqfyt
qwerywqfyt
gets()的缺点:
gets()的唯一参数是words,它无法检查数组是否装得下输入行
如果输入的字符串过长,会导致缓冲区溢出,可能会擦写掉程序中的其它数据
9.2.3 fgets(),fputs()
fgets()函数通过第2个参数限制读入的字符数。该函数专门设计用于处理文件输入,所以一般情况下可能不太好用
fgets()和gets()的区别
- fgets()函数的第2个参数指明了读入字符的最大数量。如果该参数是n,那么fgets()将读入n-1个字符,或者读到遇到的第一个换行符为止
- 如果fgets()读到一个换行符,会把它存储在字符串中。gets()会丢弃换行符
- fgets()函数的第3个参数指明要读入的文件。如果读入从键盘输入的数据,则以stdin(标准输入)作为参数,该标识符定义在stdio.h中
因为fgets()函数把换行符放在字符串的末尾,通常要与fputs()函数配对使用。如果要显示在计算机显示器上,应使用stdout作为参数
#include <stdio.h>
#define STLEN 14
int main(void) {
char words[STLEN];
//第一次输入
puts("Enter a string, please.");
fgets(words, STLEN, stdin);
printf("Your string twice (puts(), than fputs()):\n");
puts(words);
fputs(words, stdout);
//第二次输入
puts("Enter another string, please.");
fgets(words, STLEN, stdin);
printf("Your string twice (puts(), than fputs()):\n");
puts(words);
fputs(words, stdout);
puts("Done.");
return 0;
}
输出结果:
Enter a string, please.
justugly
Your string twice (puts(), than fputs()):
justuglyjustugly
Enter another string, please.
12345678901234567890
Your string twice (puts(), than fputs()):
1234567890123
1234567890123Done.
第1次输入未超过大小限制,所以\n被存储在数组中,puts()又添加了换行符,所以一行是空着的,而fputs()不添加换行符
第2次输入超过了大小限制,所以数组中没有\n,puts()添加了换行符,正常换行,fputs()不会换行
fputs()函数返回指向char的指针。如果顺利,该函数返回的地址与传入的第1个参数相同。如果函数读到文件末尾,它将返回一个特殊的指针:空指针(NULL)
#include<stdio.h>
#define STLEN 10
int main(void){
char words[STLEN];
puts("Enter strings (empty line to quit):");
while(fgets(words, STLEN, stdin) != NULL && words[0] != '\n')
fputs(words, stdout);
puts("Done.");
return 0;
}
输出结果:
Enter strings (empty line to quit):
helloworld
helloworld
qwertyuuiop
qwertyuuiop
aqzswxedcrfvtgbnhyjmukilop
aqzswxedcrfvtgbnhyjmukilopDone.
- 程序中的fgets()一次读入STLEN-1个字符,储存,然后fputs()打印该字符串
- 然后while循环进入下一轮迭代,从剩余的输入中读入数据
- 当读入并打印\n后,会进行换行
处理换行符:
while(words[i] != '\n')
i++;
words[i] = '\0';
丢弃多出的字符:
while(getchar() != '\n') //读取但不储存输入,包括\n
continue;
9.2.4 gets_s()函数
gets_s()函数和fgets()函数类似,区别如下:
- gets_s()只从标准输入中读取数据,所以没有第3个数据
- 如果gets_s()读到换行符,会丢弃它而不是储存它
- 如果gets_s()读到最大字符数都没有读到换行符:首先把目标数组中的首字符设置为空字符,读取并丢弃随后的输入直至读到换行符或文件结尾,然后返回空指针(读取失败返回NULL并清空输入)
因为第3点,gets_s()完全没有fgets()函数方便,灵活
9.2.5 scanf()函数
scanf()函数更像是“获取单词”函数,而不是“获取字符串”函数
该函数从第1个非空白字符作为字符串的开始,如果使用%s转换说明,以下一个空白字符作为字符串的结束或者读到指定长度字段后结束(如果指定了的话)
| 输入语句 | 原输入序列(▢表示空格) | name中的内容 | 剩余输入序列 |
|---|---|---|---|
| scanf("%s",name); | Fleebert▢Hup | Fleebert | ▢Hup |
| scanf("%5s",name); | Fleebert▢Hup | Fleeb | ert▢Hup |
| scanf("%5s",name); | Ann▢Ular | Ann | ▢Ular |
scanf()函数返回一个整数值,等于scanf()成功读取的项数或EOF(读到文件末尾时)
EOF:End-Of-File
scanf("%s %10s", name1, name2); //读取项数为2
scanf("%s %10s", name1, name2, name3); //读取项数为3
9.2.6 getchar()函数
定义在stdio.h头文件,用于字符输入,不带任何参数,它从输入队列中返回下一个字符
ch = getchar();
9.3 字符串输出
9.3.1 puts()函数
需要把字符串的地址作为参数传递给它
#include<stdio.h>
#define DEF "I am a #defined string."
int main(void){
char str1[80] = "An array was initialized to me.";
const char *str2 = "A pointer was initialized to me.";
puts("I'm an argument to puts().");
puts(DEF);
puts(str1);
puts(str2);
puts(&str1[5]);
puts(str2 + 4);
return 0;
}
输出结果:
I'm an argument to puts().
I am a #defined string.
An array was initialized to me.
A pointer was initialized to me.
ray was initialized to me.
inter was initialized to me.
puts()在显示字符串时,遇到空字符就停止输出,自动在其末尾添加一个换行符
9.3.2 fputs()函数
fputs()函数是puts()针对文件的定制版本,区别:
- fputs()函数的第2个参数指明要写入数据的文件。如果要打印在显示器上,可以用定义在stdio.h中的stdout作为该参数
- fputs()不会在输出的末尾添加换行符
根据添加换行符的情况,建议让puts()和gets()配对使用,fputs()和fgets()混合使用
不建议使用gets()
9.3.3 printf()函数
printf()比puts()更加多才多艺,可以格式化不同的数据类型
printf()不会在每个字符串末尾加上一个换行符,所以要加上\n换行符
9.3.4 putchar()函数
putchar()函数打印它的参数,把参数里面的值作为字符打印出来
putchar(ch);
9.4 自定义输入/输出函数
完全可以在getchar()和putchar()的基础上自定义所需的函数
例:一个类似puts()但是不会自动添加换行符的函数
#include<stdio.h>
void put1(const char * string){
while(*string != '\0')
putchar(*string++);
}
例:一个类似puts()而且给出待打印字符的个数的函数
#include<stdio.h>
int put2(const char * string){
int const = 0;
while(*string){
putchar(*string++);
count++;
}
putchar('\n'); //不统计换行符
return(count);
}
9.5 字符串函数
常用的:
- strlen(),strnlen()
- strcat(),strcat_s(),strncat(),strncat_s()
- strcmp(),strncmp()
- strcpy(),strcpy_s(),strncpy(),strncpy_s()
- sprintf(),sprintf_s(),snprintf(),snprintf_s()
除了sprintf()函数类在stdio.h头文件中声明,其余函数都在string.h头文件中声明
9.5.1 strlen()函数
该函数用于统计字符串的长度
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "abcdef";
size_t length = strlen(str);
printf("字符串\"%s\"的长度是 %zu\n", str, length);
return 0;
}
输出结果:
字符串"abcdef"的长度是 6
9.5.2 strnlen()函数
strnlen() 是 C 标准库中用于计算字符串长度的函数,但与 strlen() 不同的是,它允许指定一个最大字符数作为限制,以防止在非终止的字符串上进行无限制的长度计算,避免越界访问或潜在的缓冲区溢出问题。
- 接受两个参数:要计算长度的字符串和最大字符数限制。
- 从字符串的第一个字符开始计数,直到遇到字符串的空终止符
\0或达到指定的最大字符数为止。 - 返回的值是字符串的长度(不包括空终止符
\0),但不会超过所设定的最大字符数。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str[] = "Hello, world!";
size_t len = strnlen(str, 5); // 限制最大字符数为5
printf("字符串的长度是:%zu\n", len);
return 0;
}
示例输出:
字符串的长度是:5
要点:
strnlen()返回的值不会超过指定的最大字符数限制。例如,如果字符串长度为 12,但指定的最大字符数为 5,则strnlen()会返回 5。- 如果字符串在最大字符数范围内就已经结束(遇到
\0),函数返回实际的字符串长度。 - 该函数对非空终止的内存区域特别有用,因为它能防止扫描超出特定的内存范围,减少溢出和越界访问的风险。
注意事项:
strnlen()并不会修改字符串,它只是用于计算长度。- 在处理来自不受信任或无法保证格式的外部数据时,使用
strnlen()比strlen()更加安全,因为它可以避免因缺失终止符而导致的无限制遍历。
总结:
strnlen() 是 strlen() 的安全版本之一,它增加了最大字符数限制,防止缓冲区越界访问。当处理可能没有空终止符的字符串或需要确保在固定范围内查找字符串长度时,strnlen() 是一个非常有用的工具。
9.5.3 strcat()函数
用于拼接字符串
- 接受两个字符串作为参数
- 把第2个字符串的备份附加在第1个字符串末尾
- 把拼接后的新字符串作为第1个字符串,第2个字符串不变
strcat()函数返回第1个字符串的地址
#include <stdio.h>
#include <string.h>
int main()
{
char str1[20] = "Hello, ";
char str2[] = "world!";
strcat(str1, str2);
printf("连接后的字符串是:%s\n", str1);
return 0;
}
9.5.4 strcat_s()函数
strcat_s() 是 C11 标准引入的一个安全版本的字符串拼接函数。与 strcat() 不同,它增加了对目标缓冲区大小的检查,防止因目标缓冲区溢出而导致的潜在安全问题。
- 接受三个参数:目标字符串、目标缓冲区的大小、源字符串。
- 将源字符串的内容拼接到目标字符串末尾,并确保不会超出目标缓冲区的大小。
- 如果目标缓冲区不够大,函数会返回错误值并不执行拼接操作。
- 与
strcat()不同的是,它对目标缓冲区大小进行了严格检查,增强了代码的安全性。
strcat_s() 函数返回一个错误代码,而不是字符串地址。常见返回值包括:
0:拼接成功。- 非零值:表示发生错误(例如目标缓冲区不足)。
示例代码:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[20] = "Hello, ";
char str2[] = "world!";
errno_t result = strcat_s(str1, sizeof(str1), str2);
if (result == 0) {
printf("连接后的字符串是:%s\n", str1);
} else {
printf("拼接失败,缓冲区可能溢出\n");
}
return 0;
}
要点:
- 在使用
strcat_s()时,确保提供的目标缓冲区足够大,以便容纳拼接后的字符串。 strcat_s()在检测到缓冲区溢出的潜在风险时,会停止拼接并返回错误代码,防止内存溢出等问题。
在Visual Studio 2022 中,strcat()是不被允许的函数,因为有安全风险
9.5.5 strncat()函数
strncat() 是标准 C 库中用于字符串拼接的函数,但与 strcat() 不同的是,它允许指定拼接的字符数,提供了对拼接长度的控制,从而避免了拼接过长导致的缓冲区溢出问题。
- 接受三个参数:目标字符串、源字符串、要拼接的最大字符数。
- 从源字符串中复制指定数量的字符,并将它们附加到目标字符串的末尾。目标字符串必须足够大以容纳拼接的结果。
strncat()确保目标字符串末尾有一个空字符\0,以保证是一个正确的 C 字符串。- 尽管
strncat()限制了拼接字符数,但它并不检查目标缓冲区的大小。因此,开发者需要确保目标缓冲区足够大以容纳拼接后的结果,包括终止符\0。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[20] = "Hello, ";
char str2[] = "world!";
strncat(str1, str2, 3); // 只拼接str2的前三个字符
printf("连接后的字符串是:%s\n", str1);
return 0;
}
示例输出:
连接后的字符串是:Hello, wor
要点:
- 第三个参数指定了从源字符串中最多拼接的字符数。这个参数不会包含空终止符,所以目标字符串必须足够大以容纳拼接后的字符和最终的
\0。 strncat()适合用于只需拼接部分字符串的场景,例如只拼接固定长度的前缀或截取一部分字符串。- 与
strcat()不同,strncat()的设计是为了在某种程度上限制过长拼接导致的缓冲区溢出,但它仍然需要开发者手动管理目标缓冲区的大小。
注意事项:
尽管 strncat() 提供了拼接字符数的限制,它仍然不能完全防止缓冲区溢出,尤其是在目标缓冲区长度管理不当时。如果需要更强的安全性,建议使用 strcat_s() 这样的安全函数。
9.5.6 strncat_s()函数
strncat_s() 是 C11 标准引入的安全版本的字符串拼接函数,提供了对 strncat() 的改进,增加了对目标缓冲区的大小检查,以防止缓冲区溢出,并允许指定要拼接的最大字符数。
- 接受四个参数:目标字符串、目标缓冲区的大小、源字符串、要拼接的最大字符数。
- 从源字符串中复制指定数量的字符,并将它们附加到目标字符串末尾。与
strncat()不同,strncat_s()检查目标缓冲区是否足够大,以防止拼接时超出缓冲区的大小。 - 如果目标缓冲区不够大,
strncat_s()会返回错误值,并不会执行拼接操作。 strncat_s()保证目标字符串末尾有一个空字符\0,即使拼接失败。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[20] = "Hello, ";
char str2[] = "world!";
errno_t result = strncat_s(str1, sizeof(str1), str2, 3); // 只拼接str2的前三个字符
if (result == 0) {
printf("连接后的字符串是:%s\n", str1);
} else {
printf("拼接失败,缓冲区可能溢出\n");
}
return 0;
}
示例输出:
连接后的字符串是:Hello, wor
要点:
strncat_s()的第四个参数指定从源字符串中最多拼接的字符数(不包含空终止符)。- 目标缓冲区的大小必须通过第二个参数显式传递给函数。
strncat_s()会检查缓冲区大小,并在目标缓冲区不足时防止拼接。 - 该函数返回一个错误代码,用于指示操作是否成功。常见返回值包括:
0:拼接成功。- 非零值:表示错误,通常是因为目标缓冲区不够大。
关键点:
- 与
strncat()不同,strncat_s()是专为增强安全性设计的。它在缓冲区溢出风险较高的场景下,提供了更强的保护。 strncat_s()会在检测到缓冲区不足时,确保目标字符串的安全性,不执行拼接并返回错误代码。- 当需要严格控制字符串拼接的安全性并防止缓冲区溢出时,建议优先使用
strncat_s()。
总结:
strncat_s() 是 strncat() 的安全替代品,增加了对目标缓冲区的检查并提供了出错处理机制,从而使代码更加健壮和安全。
9.5.7 strcmp()函数
strcmp() 是 C 标准库中的字符串比较函数,用于逐字符比较两个字符串的 ASCII 值,直到找到不同字符或遇到字符串的结尾。通过比较两个字符串来确定它们是相等、前者小于后者,还是前者大于后者。
- 接受两个参数:两个需要比较的字符串。
- 按字符比较字符串的 ASCII 值,比较从第一个字符开始,依次向后,直到遇到不同字符或遇到空终止符
\0。 - 返回值为整数:
0:表示两个字符串相等。- 小于
0:表示第一个字符串小于第二个字符串(在字典顺序上)。 - 大于
0:表示第一个字符串大于第二个字符串(在字典顺序上)。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[] = "Hello";
char str2[] = "World";
int result = strcmp(str1, str2);
if (result == 0) {
printf("两个字符串相等。\n");
} else if (result < 0) {
printf("第一个字符串小于第二个字符串。\n");
} else {
printf("第一个字符串大于第二个字符串。\n");
}
return 0;
}
示例输出:
第一个字符串小于第二个字符串。
要点:
strcmp()按照字符的 ASCII 值逐个进行比较,哪一个字符串首先遇到不同的字符,比较就会终止。比较结果基于这两个字符的 ASCII 差值。- 如果一个字符串是另一个字符串的前缀,例如
"abc"和"abcd",则较短的字符串会被认为小于较长的字符串。 strcmp()不区分大小写,因此"abc"和"ABC"会被认为是不同的字符串,因为它们的 ASCII 值不同。
注意事项:
- 由于
strcmp()使用 ASCII 码进行比较,所以它区分大小写。如果不需要区分大小写,可以使用strcasecmp()(非标准)等函数。 - 如果在比较字符串的长度和内容时需要考虑到 Unicode 或其他复杂编码方式,可能需要使用不同的库或方法来进行更复杂的字符串比较。
总结:
strcmp() 是一个基础的字符串比较函数,它通过逐字符比较两个字符串的 ASCII 值来确定它们的大小关系。它常用于字典排序、字符串比较等场景,但在处理特殊编码(如 Unicode)时可能需要更加复杂的比较函数。
9.5.8 strncmp()函数
strncmp() 是 C 标准库中的字符串比较函数,它类似于 strcmp(),但允许指定要比较的字符数,这为字符串比较提供了更大的灵活性,特别是在只需要比较前 n 个字符的场景下。
- 接受三个参数:两个需要比较的字符串和一个指定要比较的最大字符数。
- 按字符比较两个字符串的前 n 个字符,直到遇到不同字符、空终止符
\0或达到指定的字符数为止。 - 返回值为整数:
0:表示两个字符串在前 n 个字符内相等。- 小于
0:表示第一个字符串小于第二个字符串(在字典顺序上)。 - 大于
0:表示第一个字符串大于第二个字符串(在字典顺序上)。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char str1[] = "Hello, world!";
char str2[] = "Hello, everyone!";
int result = strncmp(str1, str2, 6); // 只比较前6个字符
if (result == 0) {
printf("两个字符串在前6个字符内相等。\n");
} else if (result < 0) {
printf("第一个字符串在前6个字符内小于第二个字符串。\n");
} else {
printf("第一个字符串在前6个字符内大于第二个字符串。\n");
}
return 0;
}
示例输出:
两个字符串在前6个字符内相等。
要点:
strncmp()会比较两个字符串的前 n 个字符或直到其中一个字符串的结束。它不会超出指定的最大字符数范围。- 如果 n 超过了字符串的实际长度,
strncmp()只比较到遇到空终止符为止。 - 与
strcmp()一样,strncmp()也区分大小写,因此"abc"和"ABC"会被认为不同。
注意事项:
- 由于
strncmp()使用了 ASCII 比较,它区分大小写。对于不区分大小写的比较,可以使用strncasecmp()(非标准)。 - 当只需要比较字符串的部分前缀时,
strncmp()提供了更灵活的控制。
总结:
strncmp() 是 strcmp() 的扩展版,允许开发者指定最大比较字符数,从而可以只比较两个字符串的前 n 个字符。这在处理部分字符串比较或前缀比较时尤为有用。
9.5.9 strcpy()函数
strcpy() 是 C 标准库中的字符串拷贝函数,用于将源字符串的内容复制到目标字符串中,包含终止字符 \0。该函数不会检查目标缓冲区的大小,因此开发者需要确保目标缓冲区足够大以容纳源字符串及其终止符。
- 接受两个参数:目标字符串和源字符串。
- 将源字符串的内容逐字符复制到目标字符串中,包括空终止符
\0。 - 返回目标字符串的指针。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char src[] = "Hello, world!";
char dest[20];
strcpy(dest, src);
printf("源字符串是:%s\n", src);
printf("目标字符串是:%s\n", dest);
return 0;
}
示例输出:
源字符串是:Hello, world!
目标字符串是:Hello, world!
要点:
strcpy()会将源字符串的所有字符,包括空终止符\0,复制到目标字符串中,因此目标字符串的大小必须足够大以容纳整个源字符串。- 如果目标字符串的缓冲区不够大,可能会导致缓冲区溢出,引发潜在的安全问题。
注意事项:
strcpy()不检查目标缓冲区的大小,这意味着开发者必须手动确保目标缓冲区有足够的空间容纳源字符串。如果目标缓冲区不足,可能会导致未定义行为,甚至内存泄漏或崩溃。- 对于更安全的字符串拷贝,C11 标准引入了
strcpy_s(),它会检查目标缓冲区的大小,防止缓冲区溢出。
总结:
strcpy() 是一个基础的字符串复制函数,但它没有提供对目标缓冲区大小的检查,因此在使用时必须格外小心,确保目标缓冲区足够大。如果需要增强的安全性,建议使用 strcpy_s() 或类似的安全版本。
9.5.10 strcpy_s()函数
strcpy_s() 是 C11 标准引入的安全字符串拷贝函数,是 strcpy() 的增强版。与 strcpy() 不同,strcpy_s() 增加了对目标缓冲区大小的检查,防止缓冲区溢出,从而提升了字符串拷贝操作的安全性。
- 接受三个参数:目标字符串、目标缓冲区的大小(以字节为单位)、源字符串。
- 将源字符串的内容复制到目标字符串中,包括终止字符
\0。 - 在拷贝前检查目标缓冲区的大小,如果目标缓冲区不够大以容纳源字符串及其终止符,拷贝操作将不会执行,并返回错误代码。
- 返回值为错误代码:
0:表示复制成功。- 非零值:表示复制失败,常见错误包括目标缓冲区不够大。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char src[] = "Hello, world!";
char dest[20];
errno_t result = strcpy_s(dest, sizeof(dest), src);
if (result == 0) {
printf("目标字符串是:%s\n", dest);
} else {
printf("拷贝失败,缓冲区不够大。\n");
}
return 0;
}
示例输出:
目标字符串是:Hello, world!
要点:
strcpy_s()在复制源字符串之前,会检查目标缓冲区的大小,确保其足够容纳源字符串以及空终止符\0。- 如果目标缓冲区不够大,函数会返回非零错误代码,且不会进行任何拷贝操作,防止了缓冲区溢出。
注意事项:
strcpy_s()的第二个参数必须传递目标缓冲区的大小,以防止内存溢出。因此,确保正确传递缓冲区大小非常重要。- 使用
strcpy_s()可以显著提高代码的安全性,尤其是在处理动态输入或不确定源字符串长度的情况下。 - 与
strcpy()不同,strcpy_s()不会忽略潜在的缓冲区问题,而是会中断操作,避免出现未定义行为。
总结:
strcpy_s() 是 strcpy() 的安全替代品,增加了缓冲区检查,防止缓冲区溢出问题。当编写涉及字符串复制的安全代码时,建议优先使用 strcpy_s(),特别是在需要处理不确定的字符串长度时。
9.5.11 strncpy()函数
strncpy() 是 C 标准库中的字符串复制函数,它与 strcpy() 类似,但允许指定要复制的最大字符数,从而为字符串复制操作提供了更多的控制。这在需要复制部分字符串或避免缓冲区溢出时非常有用。
- 接受三个参数:目标字符串、源字符串、要复制的最大字符数。
- 将源字符串的前 n 个字符(包括空终止符
\0)复制到目标字符串中。如果源字符串长度小于 n,目标字符串会被填充空字符\0,确保正确的字符串终止。如果源字符串长于 n,则不会复制空终止符。 - 不保证目标字符串会自动以
\0结尾,除非源字符串长度小于指定的字符数。 - 返回目标字符串的指针。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char src[] = "Hello, world!";
char dest[20];
strncpy(dest, src, 5); // 只复制前5个字符
dest[5] = '\0'; // 手动添加终止符
printf("目标字符串是:%s\n", dest);
return 0;
}
示例输出:
目标字符串是:Hello
要点:
strncpy()的第三个参数指定了要复制的最大字符数。如果源字符串的长度小于 n,目标字符串的剩余部分将用空字符\0填充。- 如果源字符串的长度大于或等于 n,目标字符串中将不会自动添加空终止符,可能导致未定义行为。因此,开发者应手动在目标字符串末尾添加空终止符。
strncpy()适合用于部分字符串复制或当需要严格控制复制的字符数时使用。
注意事项:
strncpy()的一个常见陷阱是,它不会自动添加终止符\0(如果复制的字符数正好等于或大于源字符串的长度)。这意味着开发者在复制后需要手动添加终止符以确保字符串的正确性。- 如果目标字符串的长度不足以容纳 n 个字符,则可能导致缓冲区溢出。因此,确保目标字符串有足够的空间非常重要。
总结:
strncpy() 是一个灵活的字符串复制函数,允许开发者指定最大字符数进行复制。它适用于部分字符串复制或防止缓冲区溢出的场景,但使用时需要特别注意手动管理目标字符串的空终止符,确保复制后的字符串能够正确结束。
9.5.12 strncpy_s()函数
strncpy_s() 是 C11 标准引入的安全字符串复制函数,是 strncpy() 的增强版本。与 strncpy() 不同,strncpy_s() 增加了对目标缓冲区大小的检查,防止缓冲区溢出问题,确保更加安全的字符串复制操作。
- 接受四个参数:目标字符串、目标缓冲区的大小(以字节为单位)、源字符串、要复制的最大字符数。
- 将源字符串的前 n 个字符(包括空终止符
\0)复制到目标字符串中。与strncpy()不同的是,如果目标缓冲区不够大,strncpy_s()会返回错误代码,并且不会进行任何复制操作。 - 复制后,保证目标字符串以
\0终止,即使源字符串长度小于 n 或复制失败。 - 返回值为错误代码:
0:表示复制成功。- 非零值:表示复制失败,例如目标缓冲区不足或参数不合法。
使用示例:
#include <stdio.h>
#include <string.h>
int main()
{
char src[] = "Hello, world!";
char dest[20];
errno_t result = strncpy_s(dest, sizeof(dest), src, 5); // 只复制前5个字符
if (result == 0) {
printf("目标字符串是:%s\n", dest);
} else {
printf("复制失败,缓冲区可能不够大。\n");
}
return 0;
}
示例输出:
目标字符串是:Hello
要点:
strncpy_s()会检查目标缓冲区的大小,确保它足够容纳要复制的字符数和终止符\0。如果目标缓冲区不足,函数会返回错误,并且不会进行复制操作。- 与
strncpy()不同,strncpy_s()总是会确保目标字符串以\0终止,即使在复制失败的情况下。 - 该函数有助于避免缓冲区溢出等常见的安全问题,是
strncpy()的安全替代方案。
注意事项:
strncpy_s()的第二个参数必须准确传递目标缓冲区的大小,以确保它能够进行适当的安全检查。- 与
strncpy()一样,strncpy_s()适用于部分字符串复制,但其设计强调安全性,因此在目标缓冲区管理不当时可以避免潜在的缓冲区溢出问题。
总结:
strncpy_s() 是 strncpy() 的安全版本,增加了对目标缓冲区大小的检查和返回错误代码的机制,确保字符串复制操作更加安全。它是处理字符串复制时的一个推荐选择,尤其是在处理动态输入或不确定长度的字符串时。
9.5.13 sprintf()函数
sprintf() 是 C 标准库中的格式化输出函数,用于将格式化的数据写入一个字符串中,而不是像 printf() 那样输出到标准输出(通常是屏幕)。它可以根据指定的格式将各种类型的数据转换为字符串,并存储到目标缓冲区中。
- 接受的第一个参数是目标字符串(通常是字符数组),后续参数是格式字符串和要格式化的数据。
- 按照格式字符串指定的格式,将数据格式化为字符串并存储到目标字符串中。
- 返回值为写入到目标字符串中的字符数(不包括终止符
\0)。
使用示例:
#include <stdio.h>
int main()
{
char buffer[50];
int a = 10;
float b = 5.25;
sprintf(buffer, "整数: %d, 浮点数: %.2f", a, b);
printf("格式化后的字符串是:%s\n", buffer);
return 0;
}
示例输出:
格式化后的字符串是:整数: 10, 浮点数: 5.25
要点:
sprintf()的功能与printf()类似,区别在于它将格式化的输出写入到目标字符串,而不是打印到标准输出中。- 常用的格式化符号包括:
%d:整数。%f:浮点数。%s:字符串。%c:字符。%.2f:保留两位小数的浮点数。
- 目标字符串必须有足够的空间容纳格式化后的结果,否则可能导致缓冲区溢出。
注意事项:
sprintf()不会检查目标缓冲区的大小,因此如果格式化后的内容超过缓冲区大小,可能导致缓冲区溢出,产生安全隐患。- 为了避免缓冲区溢出问题,建议使用
snprintf()或sprintf_s()这样的安全版本,它们能够限制输出的字符数。
总结:
sprintf() 是一种将格式化数据写入字符串的函数,提供了灵活的格式化选项,但使用时需要确保目标缓冲区足够大以容纳格式化后的数据。在涉及潜在安全问题时,应优先使用安全版本如 snprintf() 或 sprintf_s()。
9.5.14 sprintf_s()函数
sprintf_s() 是 C11 标准引入的安全版本的 sprintf() 函数,主要目的是防止缓冲区溢出等安全问题。与 sprintf() 不同,sprintf_s() 要求显式传递目标缓冲区的大小,并在写入数据时检查该大小,确保不会发生缓冲区溢出。
- 第一个参数是目标字符串(通常是字符数组),第二个参数是目标缓冲区的大小(以字节为单位),后续参数是格式字符串和要格式化的数据。
- 按照格式字符串指定的格式,将数据格式化为字符串并存储到目标字符串中,并确保目标缓冲区不会溢出。
- 如果缓冲区的大小不足以容纳格式化后的字符串,
sprintf_s()将返回错误代码并不会执行写入操作。 - 返回值为成功写入到目标字符串中的字符数(不包括终止符
\0),如果发生错误则返回负值。
使用示例:
#include <stdio.h>
int main()
{
char buffer[50];
int a = 10;
float b = 5.25;
errno_t result = sprintf_s(buffer, sizeof(buffer), "整数: %d, 浮点数: %.2f", a, b);
if (result == 0) {
printf("格式化后的字符串是:%s\n", buffer);
} else {
printf("格式化失败,缓冲区不足。\n");
}
return 0;
}
示例输出:
格式化后的字符串是:整数: 10, 浮点数: 5.25
要点:
sprintf_s()的第二个参数明确要求传入目标缓冲区的大小。函数会根据这个大小进行写入操作,确保不会发生缓冲区溢出。- 该函数在缓冲区不足时会返回错误,不会执行写入操作,避免产生安全隐患。
- 与
sprintf()相比,sprintf_s()提供了更高的安全性,适用于需要严格管理内存的场景。
注意事项:
sprintf_s()是 C11 标准的一部分,部分编译器可能不完全支持。如果不支持,可以使用snprintf()作为替代。- 使用
sprintf_s()时,必须准确传递目标缓冲区的大小,否则可能导致无法正确处理数据。
总结:
sprintf_s() 是 sprintf() 的安全替代版,增加了对目标缓冲区大小的检查,防止缓冲区溢出问题。它是编写安全代码的推荐选择,特别是在处理不受信任的数据或需要确保内存安全的场合。
9.5.15 snprintf()函数
snprintf() 是 C 标准库中的格式化输出函数,它是 sprintf() 的安全版本之一,用于将格式化的数据写入字符串中。与 sprintf() 不同的是,snprintf() 限制了写入的最大字符数,防止缓冲区溢出问题。
- 接受的第一个参数是目标字符串(通常是字符数组),第二个参数是目标缓冲区的大小(包括终止符
\0),后续参数是格式字符串和要格式化的数据。 - 按照格式字符串指定的格式,将数据格式化为字符串并存储到目标字符串中,但不会超过指定的缓冲区大小,确保缓冲区不会溢出。
- 如果格式化后的字符串超过了指定的缓冲区大小,
snprintf()会截断字符串,并保证以\0结束。 - 返回值是格式化后的完整字符串的长度(不包括终止符
\0)。如果返回的值大于或等于提供的缓冲区大小,表示目标缓冲区不足,数据被截断。
使用示例:
#include <stdio.h>
int main()
{
char buffer[20];
int a = 10;
float b = 5.25;
int result = snprintf(buffer, sizeof(buffer), "整数: %d, 浮点数: %.2f", a, b);
if (result >= 0 && result < sizeof(buffer)) {
printf("格式化后的字符串是:%s\n", buffer);
} else {
printf("缓冲区不足,字符串被截断。\n");
}
return 0;
}
示例输出:
格式化后的字符串是:整数: 10, 浮点数: 5.25
要点:
snprintf()的第二个参数指定了缓冲区的最大大小(包括终止符\0)。该函数会确保不会写入超过此大小的字符,防止缓冲区溢出。snprintf()的返回值是格式化后的完整字符串的长度,而不管是否被截断。因此,返回值可以用于检测缓冲区是否足够大:如果返回值大于或等于缓冲区大小,说明字符串被截断。- 即使发生截断,
snprintf()也会保证目标字符串以\0结尾。
注意事项:
snprintf()不会自动为你调整缓冲区大小。如果你希望获得完整的输出,你可以检查返回值并根据需要调整缓冲区的大小。- 与
sprintf()不同,snprintf()更适合需要控制输出大小的场景,特别是在处理用户输入或其他动态数据时。
总结:
snprintf() 是一种安全的格式化输出函数,它通过限制输出到目标字符串的最大字符数来防止缓冲区溢出问题。在需要处理动态或不确定大小的字符串时,snprintf() 是一个比 sprintf() 更安全的选择。
9.5.16 snprintf_s()函数
snprintf_s() 是 C11 标准引入的一个安全版本的 snprintf() 函数,它结合了 snprintf() 的功能,同时提供了更严格的安全性检查,特别是在缓冲区管理方面。与 snprintf() 相比,snprintf_s() 要求传递目标缓冲区的大小,并会在检测到缓冲区不足时返回错误代码。
- 接受的第一个参数是目标字符串,第二个参数是目标缓冲区的大小,第三个参数是写入的最大字符数(通常与缓冲区大小相同),后续参数是格式字符串和要格式化的数据。
snprintf_s()会根据格式字符串,将格式化的数据写入目标字符串,最多写入指定大小的字符,并确保字符串终止于\0。- 如果缓冲区不足,函数会返回错误代码,并且不会导致缓冲区溢出。
- 返回值为成功写入的字符数,或者返回错误代码以指示操作失败。
使用示例:
#include <stdio.h>
int main()
{
char buffer[20];
int a = 10;
float b = 5.25;
errno_t result = snprintf_s(buffer, sizeof(buffer), _TRUNCATE, "整数: %d, 浮点数: %.2f", a, b);
if (result >= 0) {
printf("格式化后的字符串是:%s\n", buffer);
} else {
printf("缓冲区不足,格式化失败。\n");
}
return 0;
}
示例输出:
格式化后的字符串是:整数: 10, 浮点数: 5.25
要点:
snprintf_s()的第二个参数是缓冲区的大小,确保不会写入超过此大小的字符,防止缓冲区溢出。- 第三个参数
_TRUNCATE表示在缓冲区不足时进行截断操作。如果你不希望截断数据,可以传入实际的字符数上限,但这样可能会导致错误返回。 snprintf_s()保证即使发生截断或失败,目标字符串也会以\0终止。
注意事项:
snprintf_s()比snprintf()提供了更严格的安全性检查,在缓冲区不足时会返回错误代码,而不是像snprintf()那样截断数据并继续操作。- 使用时需要提供准确的缓冲区大小以确保安全和正确的操作。
总结:
snprintf_s() 是 snprintf() 的安全增强版,增加了对缓冲区大小的检查并引入了截断机制。它适用于需要对格式化输出进行严格缓冲区管理的场合,并确保不会发生缓冲区溢出问题。如果缓冲区管理是一个重要的考虑因素,建议优先使用 snprintf_s()。
9.6 ctype.h 字符函数和字符串
ctype.h 是 C 语言标准库的一个头文件,提供了一系列用于字符分类和转换的函数。这些函数主要用于检测字符的类型,比如字母、数字、空白等,并对字符进行大小写转换。这些功能对于文本处理和解析非常有用。下面是一些 ctype.h 中常用的函数:
isalpha(int c):检测给定的字符是否是字母(包括大写和小写)。isdigit(int c):检测给定的字符是否是数字('0' 到 '9')。isalnum(int c):检测给定的字符是否是字母或数字。isspace(int c):检测给定的字符是否是空白字符,如空格、制表符、换行符等。isupper(int c):检测给定的字符是否是大写字母。islower(int c):检测给定的字符是否是小写字母。toupper(int c):将小写字母转换为大写。tolower(int c):将大写字母转换为小写。iscntrl(int c):检查给定的字符是否是控制字符。isgraph(int c):检查给定的字符是否有图形表示(即除空格外的可打印字符)。isprint(int c):检查给定的字符是否是可打印的字符,包括空格。ispunct(int c):检查给定的字符是否是标点符号,不包括空格和字母数字字符。isxdigit(int c):检查给定的字符是否是十六进制数字('0'-'9'、'a'-'f'、'A'-'F')。
使用这些函数时,通常需要传递一个 int 类型的参数,该参数通常是一个字符(以其 ASCII 码表示)。这些函数的返回值通常是整型,对于检测函数,如果输入字符符合条件,则返回非零值(通常是 1),否则返回 0。对于转换函数,则返回转换后的字符的 ASCII 码。如果输入的字符不适用于特定的转换(如用 toupper() 转换一个已经是大写的字符),则返回输入字符本身的 ASCII 码。
这些函数的实现通常是非常高效的,它们对于在文本解析、输入验证和数据处理中快速检测和转换字符特别有用。
9.7 把字符串转化为数字
使用printf(),sprintf()函数,可以将字符转化为字符串。但如何将字符串转化为整数?
在 C 语言中,如果你有一个包含数字的字符串(例如 "1234"),并想将这个字符串转换为一个整数(例如 1234),你可以使用标准库中的一些函数来实现这一转换。最常用的函数是 atoi() 和 strtol()。
9.7.1 使用atoi()
atoi() 函数可以将字符串转换为整数。它的原型在 stdlib.h 头文件中:
int atoi(const char *str);
这个函数会扫描参数 str,跳过前面的空白字符(例如空格),直到遇到第一个数字或负号,然后开始解析,直到遇到非数字字符。
示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
char *str = "1234";
int num = atoi(str);
printf("The number is %d\n", num);
return 0;
}
这段代码会输出 1234 作为整数。
9.7.2 使用strtol()
如果你需要更健壮的错误处理或者想要解析长整数(long),可以使用 strtol() 函数。这个函数也在 stdlib.h 中定义,允许你指定数字的进制,并且能够提供更详细的错误处理。
long strtol(const char *str, char **endptr, int base);
str是包含数字的字符串。endptr是一个字符指针的指针,strtol()会设置*endptr为字符串中最后一个被解析字符的下一个字符。base指定了数字的基数,允许你从二进制到十六进制等不同进制中解析。如果设置为0,则自动从字符串格式推断进制(例如,十六进制会以0x开头)。
示例代码:
#include <stdio.h>
#include <stdlib.h>
int main() {
char *str = "1234";
char *endptr;
long num = strtol(str, &endptr, 10);
if (*endptr == '\0') { // 检查是否到达字符串末尾
printf("The number is %ld\n", num);
} else {
printf("Conversion error, non-numeric data: %s\n", endptr);
}
return 0;
}
这段代码同样会输出 1234,但它还会检查是否整个字符串都被成功解析为数字。
这两种方法都可以将字符串中的数字转换为数值类型,选择哪种方法取决于你的具体需求和对错误处理的考虑。
